Advanced querying
This topic is for advanced users who use command-line queries in the Query Builder, macros, widget scripts, or in API usage.
Polarion's query language is essentially the same as that of Apache Lucene. The syntax is documented in the Apache Lucene Syntax Documentation, available on the Apache web site.
The following tips are relevant to Lucene queries specified in Polarion:
Operators must be typed in upper case: AND, OR, NOT.
White space has the same function as the OR operator. Consequently, severity:(blocker OR critical) OR priority:(highest OR high) will return the same result as severity:(blocker critical) priority:(highest high). White space can be also used to separate different values for one term.
There is a special field HAS_VALUE, which can be used to determine whether or not an object has a value set in a field. For example, to query for items with no value in the resolution field, use NOT HAS_VALUE:resolution.
Search terms cannot start with an asterisk (*). For example, something* is a valid query, but *something is not.
Queries, including subqueries, can begin with the NOT operator: NOT severity:blocker, and severity:blocker AND (NOT priority:low OR HAS_VALUE:assignee.id) are valid queries.
However queries like QUERY1 OR NOT QUERY2 are problematic and must be written in the form QUERY1 OR (NOT QUERY2).
Operators have no defined priority, so complex queries should be surrounded by parentheses. Example:
(type:userstory AND targetRelease.KEY:1.0) OR (type:defect AND priority:highest)
Using many parenthetical expressions in queries may negatively impact performance because more time is spent in query preprocessing. To optimize the performance of your queries, consult the Apache Lucene Syntax Documentation.
The same query language is applicable in a number of administrative tasks such as customization of configuration files that contain query expressions, or elements, or attributes that consist of a query expression.
Deprecated query elements
Existing queries that use any of the constructs mentioned below still work, but are now considered deprecated and long-term support for them is not guaranteed. It is recommended that you update all such usages in saved queries, macro and page parameters in Wiki pages, API calls, etc. to the recommended form.
Work Item field CUSTOM_FIELDS - Querying the HAS_VALUE field is preferred to the CUSTOM_FIELDS field. For example, use: HAS_VALUE:targetRelease rather than CUSTOM_FIELDS:targetRelease.
Also, custom fields of type enumeration now use the .KEY variant of the field. Example: targetRelease.KEY:2.1.0, and not targetRelease:2.1.0
Query constant ######NULL - For querying objects with empty field values, you should no longer use the ######NULL query constant. Use the HAS_VALUE field instead. For example, to query for items with no value in Severity use NOT HAS_VALUE:severity instead of severity:######NULL.
Activities field FIELDS - The HAS_VALUE field is also preferred to the FIELDS field for Activities. For example, use HAS_VALUE:field instead of FIELDS:field for Activities.
Query parameters ALL:ALL_VALUE and ALL:NO_VALUE - Replace ALL:ALL_VALUE with *:*, and replace ALL:NO_VALUE with NOT *:*.
Search syntax basics
Polarion's query engine is based on Apache Lucene. Consequently, query syntax in Polarion is essentially the same as that of Lucene. You may want to download the Lucene Documentation. The following table lists some syntax constraints that are commonly needed when constructing queries in Polarion.
System Constraint | Example |
|---|---|
Word or phrase " : | "Word", "Phrase with several words" title:word title:"Phrase with several words" |
Wildcards: *, ? | ? – replaces single character * - severaltitle:ab* - finds Work Items having words starting with 'ab' in the title fieldtitle:ab*c - finds Work Items having words in the title field starting with 'ab' and finishing with 'c' The same with '?' Lucene doesn't allow using wildcards as first character Lucene expands all the wildcards to matching statements. Thus, if you type title:t*it will be expanded by Lucene to: title:the OR title:test OR title:task OR... Polarion's default is 2048 clauses maximum in one Lucene query (Lucene's default is 1024).Using too generic a wildcard may exceed this maximum number resulting in an error reported back to the user. |
Fuzzy/proximity search ~ | Tilde (~) is used for a fuzzy/proximity search. You should seldom need to use it. |
Range Searches { }, [ ] | [ ] – Specifies the range in dates or numbers, { } – Will find all Documents whose titles are between specified terms, exclusive. Example: created:[20120208 TO 20120222] finds Work Items created between 08 Feb 2012 and 22 Feb 2012 { } Rarely needed, not recommended. |
Boosting a Term ^ | ^ is used for relevant searching. In most scenarios you don't need it with Polarion |
Boolean Operations + - || && ! | Lucene supports AND, "+", OR, NOT and "-" as Boolean operators(Note: Boolean operators must be ALL CAPS) AND == && title:xxx AND severity:blocker finds Work Items where title contains 'xxx' and severity is set to 'blocker'. Similar syntax using OR. Title:xxx AND NOT severity:blocker finds elements with 'xxx' in title and with severity other than 'blocker' +/- may be used for the explicit requirement of having the record found or excluded. |
Grouping () | Group statements using parentheses. severity:(blocker OR critical) has the same result as severity:blocker OR severity:critical Grouping also makes prioritization of constraints (as in mathematics): severity:blocker AND (title:xxx OR title:yyy) will make the OR operation higher priority than comparing blocker severity with title:xxx. |
Escaping with backslash (\) | When using any characters above in text search, use '\'. For example, title.1:\(1+1\)\:2 will search Work Items with the literal value '(1+1):2' in the "title" field. |
Tokenization
Polarion supports two different tokenization algorithms. System property search.wordBoundaries can be used to select from them.
White space based:
This is the default tokenization. However, it is not convenient for languages that do not use white space between words. The indexed text is split around white spaces, and from the remaining character sequences all leading and trailing non-alphanumeric characters (anything that is not a letter or number) are removed.
For advanced users: This splitting is done using a regular expression and java.lang.String.split(String). It is possible to configure a custom regular expression that should be used via the system property search.wordBoundaries.splitByPattern.
Examples:
(Term for title.1 field is always the same as the title itself.)
Item Title | Terms for "title" field | Query | Result (standard tokenization) |
|---|---|---|---|
Mary had a little 'lamb'. | Mary, had, little, lamb | title:mary | found |
title.1:mary | not found (title.1's term is "Mary had a little lamb") | ||
title:mary* | found | ||
title.1:mary* | found | ||
SW_ngcb_simulation | SW_ngcb_simulation | title:SW | not found |
title:ngcb | not found | ||
title:SW_ngcb | not found | ||
title:SW_ngcb* | found | ||
title.1:SW_ngcb | not found (title.1's term is "SW_ngcb_simulation") | ||
title.1:SW_ngcb* | found | ||
WI-1234 | WI-1234 | title:WI | not found |
title:1234 | not found | ||
title:WI-1234 | found |
Standard Tokenization:
This method splits text into words according to the Unicode standard. To use this method of tokenization, use the system property search.wordBoundaries=standard.
Examples:
(Term for title.1 field is always the same as the title itself.)
Item Title | Terms for "title" field | Query | Result (standard tokenization) |
|---|---|---|---|
Mary had a little lamb. | Mary, had, little, lamb | title:mary | found |
title.1:mary | not found (title.1's term is "Mary had a little lamb") | ||
title:mary* | found | ||
title.1:mary* | found | ||
SW_ngcb_simulation | SW_ngcb_simulation | title:SW | not found |
title:ngcb | not found | ||
title:SW_ngcb | not found | ||
title:SW_ngcb* | found | ||
title.1:SW_ngcb | not found (title.1's term is "SW_ngcb_simulation") | ||
title.1:SW_ngcb* | found | ||
WI-1234 | WI-1234 | title:WI | found |
title:1234 | found | ||
title:WI-1234 | found (matches titles containing "WI" or "1234") |
Combining text with visual queries
If you have used the visual elements of the Query Builder to create a query, you can optionally append free-form textual query syntax. When combining visual and textual query elements, there are a few points to keep in mind:
The free-form part of query is usually connected syntactically with the visual elements by the AND operator.
For example, if you have two visual elements [Type:Requirement][Assignee:Me] (visual elements denoted here by square brackets), if you append text severity:must_have, your Query Builder line will look like [Type:Requirement][Assignee:Me] + severity:must_have, and will be treated by the query parser as: type:requirement AND assignee.id:$me AND severity:must_have.
Appending text to visual elements with the OR operator causes the leading visual elements to be treated syntactically as if they were surrounded by parentheses.
For example, if you have two visual elements [aa:xx][bb:yy] (visual elements denoted here by square brackets), if you append text OR cc:zz, your Query Builder line will look like [aa:xx][bb:yy] + OR cc:zz, and will be treated by the query parser as: (aa:xx AND bb:yy) OR cc:zz.
If the Query Builder is cleared of all visual elements, you can start the free-form part of a query with an operator. However, AND and OR are ignored. Operator NOT at the beginning of a query is parsed as you would expect.
Edit an opened query:
You may sometimes access the Work Items table via a link in an email or a shortcut containing a query, via a saved query. If the query you are opening was originally constructed with visual query elements, the visual elements appear in the Query Builder when you access the table via the link or shortcut, and you can subsequently edit the query by modifying the visual elements.
If the query you open contains any elements that cannot be parsed into visual elements, the elements which can be rendered visually are so rendered until an element that cannot be parsed into a visual element is encountered. The remaining elements are rendered as a text string. You can then modify the query any way you want, editing, adding or removing visual elements, and/or editing, removing, or modifying the text string.
Queries using special index functions
Polarion implements a number of special index functions and "query expander" variables, which can be referenced to simplify queries on complex objects... Documents or Test Records, for example. This section describes the main use cases and related special index functions.
Current-date based searches:
The Polarion query system provides a special $today$ constant that can be used in query strings to retrieve Work Items updated on the current date. This can be useful for creating shortcuts.
Allowed formats:
$today$: actual date
Modifiers can be used to shift the date to a specified time frame:
$today - SHIFT$: actual date minus time frame specified by SHIFT (see examples below)
$today + SHIFT$: actual date plus time frame specified by SHIFT
The SHIFT parameter can take the following form:
Nd: N days, where N is an integer value. For example, 14d represents a time frame of fourteen days
Nw: N weeks
Nm: N months
Ny: N years
The following example searches for items created during the previous week:
created:[$today - 2w$ TO $today - 1w$]
Spaces between $today and SHIFT$ are ignored, so expressions like $today-3w$ will work.
Query for Linked Work items:
There can sometimes be a need to query for Work Items that are linked by another Work Item according to the link role. You can formulate a query around the following elements:
linkedWorkItems
backlinkedWorkItems
Consider the following figure:
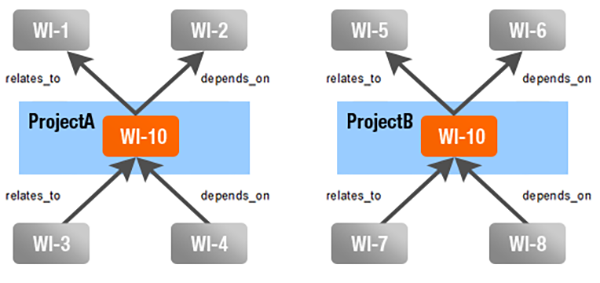
There are two Work Items having an ID of WI-10. These exist in different projects, and both have links to/from other Work Items (for the purposes of this example, it doesn't matter in which projects the linked items live).
Query | Matched Items |
|---|---|
backlinkedWorkItems:WI-10 | WI-1, WI-2, WI-5, WI-6 |
backlinkedWorkItems:ProjectA/WI-10 | WI-1, WI-2 |
backlinkedWorkItems:depends_on=WI-10 | WI-2, WI-6 |
backlinkedWorkItems:depends_on=ProjectA/WI-10 | WI-2 |
Query | Matched Items |
|---|---|
linkedWorkItems:WI-10 | WI-3, WI-4, WI-7, WI-8 |
linkedWorkItems:ProjectA/WI-10 | WI-3, WI-4 |
linkedWorkItems:depends_on=WI-10 | WI-4, WI-8 |
linkedWorkItems:depends_on=ProjectA/WI-10 | WI-4 |
Query for Test Record Work Items:
You can build queries to search for Work Items linked to a test record in a particular Test Run using the TEST_RECORDS element. This can be particularly useful when creating report pages. For example, a test manager might use it to query for what defects were part of some test results.
The element can take the following parameters:
Component | Description | Required | Attributes |
|---|---|---|---|
test run | Identifier of the Test Run whose test records should be queried for linked Work Items. Format: project ID/Test Run ID. | YES | N/A |
test result | The kind of results to search for. | NO | testResultId - identifier of a kind of result, for example,"failed", "passed", "blocked" @any - search for test records with any type of result @null - search for test records with no result * - search for all test records |
executed by | Search for test records executed by some specified user(s) | NO | userId - the user ID of a user who executed the tests of the test record * - search for all test records |
when executed | Date or time interval when execution of the Test Run of a test record occurred | NO | yyyymmdd - search for test records executed on particular day yyyymmdd TO yyyymmdd - search for test records executed in time interval * - search for all test records |
linked work item type | Type of Work Item linked to test records | NO | false (default value) - search for Test Cases linked to test records true - search for Defects linked to test records |
Examples:
Search for test cases executed in Initial System Verification Test:
TEST_RECORDS:("drivepilot/Initial System Verification Test",@any)Search for test cases planned for Initial System Verification Test, but not executed yet:
TEST_RECORDS:("drivepilot/Initial System Verification Test",@null)Search for test cases executed by mTest in last week in Full System Verification Test: TEST_RECORDS:("drivepilot/Full System Verification Test",@any,"mTest","$today-1w$ TO $today$")
Search for defects triggered by test failures in Initial System Verification Test: TEST_RECORDS:("drivepilot/Initial System Verification Test","failed",*,*,"true")
Query for Documents:
Use the document.id index field to query for a specific Document. You can use the outlineNumber index field to query for items contained in Documents according to their outline number.
Syntax: Syntax: document.id:"Space Name/Document Name"
Examples: document.id:"Functional Requirements" searches for the named Document in the default space. Note that the _default space name should not be specified. You only need to specify it in the query parameter of wiki macros such as the {workitems} macro.
Example: document.id:"Requirements/Functional Specification" searches for a Document named Functional Specification in the Requirements space.
You can query for Outline numbers in Documents using the special index field outlineNumber . The Outline Number field can be sorted on this index field. Sort is by document.outlineNumber, and wildcards are supported. Examples:
All items in current scope with outline number on level 1.1: outlineNumber:1.1.*
Unresolved items with outline number on level 1.1 in Document named FunctionalSpec located in the Specification space: NOT HAS_VALUE:resolution AND document.id:Specification/Functional Specification AND outlineNumber:1.1*
When searching for content of a particular outline number, the document to search within can also be specified.
outlineNumber:("PROJECT/SPACE/ID", "2*")When working within the Document scope (Using the filter in the document editor, the table or tree tabs), the document is automatically added to the query.
Specify a document whenever possible (in all places other than in the Document scope), otherwise the outline query will search through all the documents in the entire repository.
"OutlineNumber" queries only work when the number of Work Items that contain matching outline numbers is not greater than the value of the "luceneMaxClauseCount" Polarion Property. (The default is set to 20 000.)
Query for Approvals:
Querying for items in a particular state with regard to approval has a special syntax - see the following examples.
Items awaiting approval by a specific user (user ID "rProject"): approvals:fullxxxapprovedxxxrProject
All items disapproved by anyone: approvals:fullxxxdisapprovedxxx*
All items awaiting approval by the current user: approvals:fullxxxwaitingxxx$[user.id]
In the Work Items table, create a query using the visual query builder, selecting the Approval field and setting the desired parameters. In the helper panel, click Copy to Clipboard to access the query including the special syntax.
Query for Baselines
You can query both Document and Project Baselines with the following:
baseObject:project
(Would only search for Project Baselines.)
baseObject:document/*
(Would search for all Document Baselines.)
baseObject:"document/Specification/Formula 3"
(Would search for all Document Baselines for the Formula 3 document in the Specification Space.)
Example syntax:
$query = "baseObject:"document/Specification/Formula 3"
$baselines = $trackerService.getDataService().searchInstances("Baseline", $query, $sort)